A while back, at my current position I was assigned to investigate what seemed a really complex problem at first but slowly as I gathered more information I managed to put in place a number of steps to resolve it. Here I will detail the process which I took in order to go from being completely oblivious about a serious performance problem in production to ultimately resolve it and making the system more scalable along the way.
Some technologies covered in this post are RabbitMQ and PHP 7.4.
Problem Report
In a nutshell, the company I work for hosts these online video slot games tournaments in which thousands of players participate and play against each other with a leader-board scoring system. The incidents team from their initial analysis, have reported that from time to time, whenever one of those big tournaments finishes, the CPU on the production server spikes to 100% and the server eventually comes down. The IT have reported that this seems related to a staggering spike in PID processes which suddenly appears on the Linux server and never seem to go down consuming all the resources of the machine.
Problem Analysis
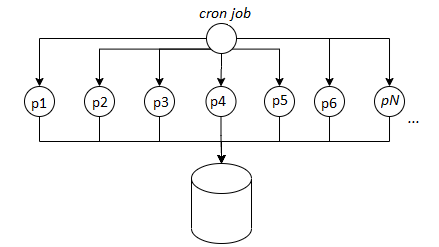
After taking a first look at the code, it was clear that the ending of these tournaments is handled via a cron-job which is executing every minute or so and then for each player participating in a tournament, a series of events are run to calculate the leader-board structure and the prize payout. In our case, we are working with PHP 7.4 and PHP is a single thread language therefore in order to achieve parallel asynchronous tasks, the [popen function] is used to create multiple forks on a separate process (PID). This seemed to be the root of the problem because a few years back when this code was created, one was not accounting for a tremendous growth of users and therefore the code worked well until hundreds of users were participating and thus creating hundreds of PIDs on the server once a tournament finished. Now with thousands of users, the situation is very different.
Possible Solutions
The goal at this point was clear: we need to limit the number of PIDs which get executed on the server so that thousands of threads trying to access the database at the same time are avoided. A few possible solutions were discussed but in the end, the one which seemed most viable was to start using queues instead of PHP forks. This would take longer to develop and get to production but in the long run it will be the more efficient and most scalable solution.
[RabbitMQ] is the choice of messaging broker at this point because it had already been used for other projects and therefore it was a familiar technology within the company despite a few caveats to be known when using PHP, one example is the [keep connection alive] issue which needed to be dealt with. The [AmqpLib] library for PHP would be used to create the publishers and the consumers.
The Plan
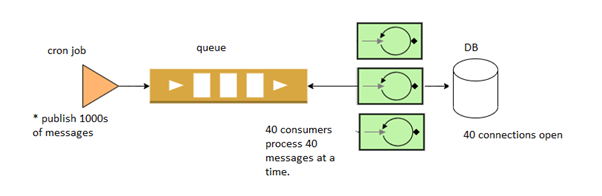
So the plan was to start moving the code which is executing in a forked process into RabbitMQ consumer processes. Using [supervisor] we were able to create multiple consumers of the same process enough to handle the volume of work within seconds but never enough to choke up all the server or database resources.
From the FPM side (web part) or the cron-job side, rather than running the fopen() function, a message was published to RabbitMQ and let the consumers take care of the work thus maintaining the asynchronous architecture.
Before:
After:
The Result Outcome
Well.. the good news is that after deploying this new architecture, the server stopped crashing and IT were very happy with us, however new problems started to emerge since the original code was not designed to work with a queuing technology. Over the following weeks (and months) we needed to do some further adjustments until all problems went away.
Below are some of the most notable improvements which were laid out to make the system more efficient.
1. Publisher Connections limit
In the error log file, hundreds of the following errors were noticed:
PHP Fatal error: Uncaught exception 'PhpAmqpLib\Exception\AMQPTimeoutException' with message 'The connection timed out after 3 sec while awaiting incoming data'It turns out that whenever a publisher needs to connect to RabbitMQ the process is quite heavy as the server needs to exchange 7 TCP packets for each connection to be established [1]. In our case, we needed to create a new connection for each message to get published and at peak times the RabbitMQ server was unable to allocate resources to accommodate all incoming traffic and thus many resulted in timeout. In order to mitigate this problem, we used [AMQProxy] by CloudAmqp which acts as a proxy between the system and the queue and keeps a pool of open connections to the queue and reuses them accordingly when new connections are requested.
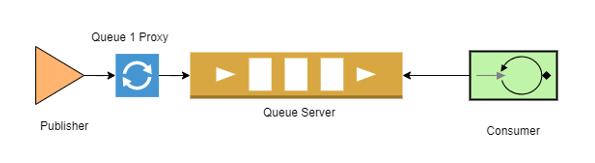
When doing benchmark testing, it seemed at first that the proxy is creating even more connections than necessary, however it was then noticed that the total connections remain stable and do not keep spiking until a deadlock is reached (as was happening before). Below are some illustrations showing the number of connections created on RabbitMQ based on the number of messages published by an internal benchmark tool:
Without Proxy (1 connection per message)::
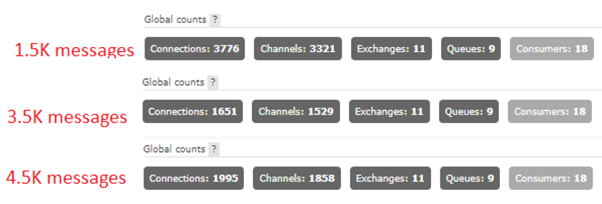
With Proxy (1 connection per message)::
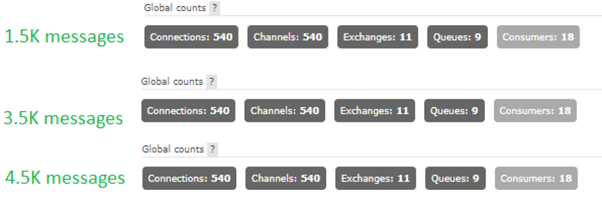
2. Race conditions
Some code which previously was being forked, was not expected that it could at times take a couple of seconds to finish. As a consequence, we experienced issues with the prize calculations during peak times where some people were not receiving the proper prize amount in the calculation. For the sake of the example, let’s imagine we were doing something like this to calculate prizes:
calculatePrizesPart1();
calculatePrizesPart2();These are always executed in this order. Then we do
publishToQueue(calculatePrizesPart1());
calculatePrizesPart2();This would mean that the first part of the code now being published to a queue might finish after the second part. For this reason some parts of the code were revisited to make sure that the entire code blocks are moved to consumers and are executing together or in the right order.
3. Unnecessary SQL bottlenecks
It was noticed that during peak times, the amount of messages arriving to queue was in the hundreds of thousands and it took up to 30 minutes to get emptied. This was causing a lot of problems because clients complain that the prize hasn’t been received in time. After analysing the code, the following logic was noticed:
// Publisher.php
$tournament = getTournamentFromDB($tournId);
$entry = getEntryFromDB($tournament->id, $userId);
publishToQueue('calculate-prize', $tournament->id, $entry-id);
// Consumer.php
processMessage($tournId, $entryId) {
$tournament = getTournamentFromDB($tournId);
$entry = getEntryFromDB($tournament->id, $userId);
calcPrize($tournament, $entry);
}Essentially for each prize calculation, we were sending the ID of the objects and then from the consumer run SQL statements again on the database to retrieve the objects again. This caused a heavy load on the database and slowed everything down. To solve this bottleneck, we took the advantage of the RabbitMQ message payload and passed the entire objects inside the message itself and thus eliminating the SQL queries on the consumer side.
// Publisher.php
$tournament = getTournamentFromDB($tournId);
$entry = getEntryFromDB($tournament->id, $userId);
publishToQueue('calculate-prize', $tournament, $entry);
// Consumer.php
processMessage($tournament, $entry) {
calcPrize($tournament, $entry);
}
Conclusion
The “fork bomb” saga as we call it internally has been quite a pain in the neck for a couple of months for a few people including myself however we have came a long way ultimately resolving it and taking with us a big deal of knowledge on improving a system performance and scalability. I hope this knowledge I’m sharing here can be useful for others too!
References
1. AmqProxy
https://github.com/cloudamqp/amqproxy
2. AmqpLib – The PHP RabbitMQ library
https://github.com/php-amqplib/php-amqplib