Back when I was studying AI and Machine Learning, I was given an assignment where I had to create an Optical Character Recognition (OCR) program using the MNIST (http://yann.lecun.com/exdb/mnist/) data set. The requirement was to create a couple of Machine Learning algorithms such as Nearest Neighbour and Multi-Layred Perceptron (more on these later) and then run a two-fold test through these algorithms to train a model to for classifying hand-written digits. The first half of the data set would be used to train the model and the second half to test the outcome prediction for the given characters ultimately calculating the percentage of accuracy in the results.
I wanted to take this a step further and create a GUI where a user could hand-write a digit and the program would try guessing the input by learning from the data set.
Check out the live demo [here].
Step 1: Examining Data
The training data which we will be working with is in CSV format and each row contains a set of 65 integer values, the first 64 being the data bits (vectors) representing the character and the last being the actual identifier (a character between 0 – 9). The data set can be found [here]. The scanned numbers have been converted from image bitmaps to 32×32 pixel format, kind of like a grid of ON and OFF values which depict the character black on white. These ON and OFF values are represented as 0s and 1s and then these bits are divided into 4×4 non-overlapping blocks.
The number of ON pixels is counted in each of these blocks to give a value between 1 and 16. This part is explained in more detail later but for now, the idea is to understand the format of the train data in order to create the same format when inserting the hand-drawn values into the program.
The SUM of each 4×4 block give the 64 bit integer sequence which will be representation of the character (0-9).
Step 2: Canvas to Pixels
The goal is to create a canvas onto which a user could write a digit using mouse or touch-pad and convert the bitmap into the same 64 bit sequence in order to run through a machine learning algorithm to predict the most likelihood of the character compared to the rest of the training data set. If we had to provide a 32×32 pixel canvas, it would be a bit too tiny to allow any scribbling as input and therefore we will create a 100×100 pixel canvas and then resize it later using a preview canvas. The code for creating user scribbling on an HTML canvas and then resizing can be found on Github [here].
When processing the canvas data, it’s vital to understand how pixels work. Each pixel is repented by 4 values: Red, Blue, Green and Alpha. I won’t get too much into detail on this since it can be looked up easily but basically for our sake, the important thing to know is that when dealing with raw canvas data, each sequence of 4 characters = 1 pixel. In this case, 32×32 pixels = 1024 bits * 4 = 4096; below is the console log of canvas.data illustrated.
The convertToGrascaleMatrix() method, loops through all these pixels and organises them into a 32×32 pixel grid array. In each iteration, the Alpha value (4th bit) is checked whether it’s a 0 (OFF) or any value between 1-255 (ON) and 1 or 0 is inserted in the array accordingly. Below is the console log of the end result, the binary output resembles the drawn image.

The next step is to send the pixels array into the count4X4MatrixSections() to create the 4×4 blocks and count the ON /OFF values inside and produce the 64 bit integer sequence to send into the machine learning algorithm.
Example in this case: 3,15,14,15,15,3,0,0,3,7,1,2,11,12,0,0,0,0,0,2,12,12,0,0,0,0,5,16,16,4,0,0,0,0,2,9,15,13,1,0,0,0,0,0,2,15,9,0,0,15,12,2,0,13,12,0,0,5,13,16,14,16,7,0,
Step 3: Machine Learning
The nearest neighbour algorithm is a good starting place for attempting to resolve the OCR problem as it will use a distance function to calculate the distance between the sums of the vectors of a given OCR character (in our case the 64 bit integers) against those in the training data set and classify the number according to its closes neighbour’s identifier. I won’t get too much into detail about the algorithm itself since I will be doing another [article] about machine learning algorithms soon, plus Google is your friend if you wish to look up the nearest neighbour algorithm and euclidean distance.
For this project, I chose to implement this algorithm and use Euclidian Distance as the distance function to predict the inserted characters. The code is in C# and can be found [here] with inline comments explaining the behaviour at each step.
Step 4: Refining Results
When I finished the first version of this project, I was getting pretty good result predictions from the algorithm but when I asked some friends to try it, the results weren’t so accurate anymore. I realised after some analysis that when I was writing the characters on the canvas I was drawing big numbers to occupy all the space in the box whilst other people weren’t.
I concluded that since the OCR training data-set is based on bitmaps of numbers which are centered and without much white bordering and white space in general that it would be a good idea to introduce a certalise and crop function in order to give the algorithm more refined data to work with. The centraliseAndCropCanvas() method is based on a few concepts which I found by research and adapted to my project, I will leave references for these below. Basically finding the bounding rectangle in the image eliminates the outer white spaces and then finding the center of mass of the character helps repositioning the character at the middle of the canvas after the cropping.
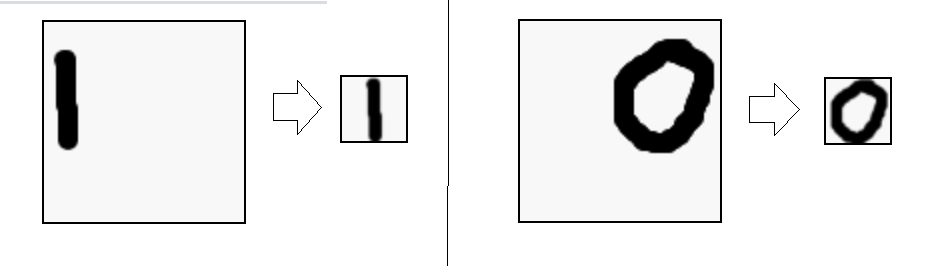
The code for these functions can be found in this JavaScript file [here]. This has drastically improved the performance of the algorithm. The preview box illustrates the final version of the drawn up character after undergoing all transformation and before being sent to the algorithm.
Conclusion
Of course, it can never reach a 100% accuracy but if you think about it, even a human being can have difficulty recognising a handwritten digit every now and then let alone a machine!
You want to try yourself? Check out the demo [here].
Full source code can be found on [Github].
What next?
I will make another [post] where I will compare other algorithms such as the kNN and the Multi-Layered Perceptron and discuss the advantages and disadvantages and try to apply the GUI created in this project on them.
Also I will be trying the ML.NET libraries for machine learning and apply the GUI to check if I get better results than my own.
References
1. Optical Recognition of Handwritten Digits Data Set:
http://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
2. The MNIST Database:
http://yann.lecun.com/exdb/mnist/
3. Using Touch Events with the HTML5 Canvas
http://bencentra.com/code/2014/12/05/html5-canvas-touch-events.html
4. Canvas bounding box
http://phrogz.net/tmp/canvas_bounding_box.html
https://stackoverflow.com/questions/9852159/calculate-bounding-box-of-arbitrary-pixel-based-drawing
5. JS – Center Image inside canvas element
https://stackoverflow.com/questions/39619967/js-center-image-inside-canvas-element